 | Real-Time Data Warehousing: |
Today's Real-time Requirement
Traditionally data warehouses do not contain today's data. They are usually loaded with data from operational systems at most weekly or in some cases nightly, but are in any case a window on the past. The fast pace of business today is quickly making these historical systems less valuable to the issues facing managers and government officials in the real world. Morning sales on the east coast will affect how stores are stocked on the west coast. Airlines and government agencies need to be able to analyze the most current information when trying to detect suspicious groups of passengers or potentially illegal activity. Fast-paced changes in the financial markets may make the personalized suggestions on a stockbroker's website obsolete by the time they are viewed.
As today's decisions in the business world become more real-time, the systems that support those decisions need to keep up. It is only natural that Data Warehouse, Business Intelligence, Decision Support, and OLAP systems quickly begin to incorporate real-time data.
Data warehouses and business intelligence applications are designed to answer exactly the types of questions that users would like to pose against real-time data. They are able to analyze vast quantities of data over time, to determine what is the best offer to make to a customer, or to identify potentially fraudulent, illegal, or suspicious activity. Ad-hoc reporting is made easy using today's advanced OLAP tools. All that needs to be done is to make these existing systems and applications work off real-time data.
This article examines the challenges of adding real-time data to these system, and presents several approaches to making real-time warehousing a reality today.
Challenge #1: Enabling Real-time ETL
One of the most difficult parts of building any data warehouse is the process of extracting, transforming, cleansing, and loading the data from the source system. Performing ETL of data in real-time introduces additional challenges. Almost all ETL tools and systems, whether based on off-the-shelf products or custom-coded, operate in a batch mode. They assume that the data becomes available as some sort of extract file on a certain schedule, usually nightly, weekly, or monthly. Then the system transforms and cleanses the data and loads it into the data warehouse.
This process typically involves downtime of the data warehouse, so no users are able to access it while the load takes place. Since these loads are usually performed late at night, this scheduled downtime typically does not inconvenience many users.
When loading data continuously in real-time, there can't be any system downtime. The heaviest periods in terms of data warehouse usage may very well coincide with the peak periods of incoming data. The requirements for continuous updates with no warehouse downtime are generally inconsistent with traditional ETL tools and systems. Fortunately, there are new tools on the market that specialize in real-time ETL and data loading. There are also ways of modifying existing ETL systems to perform real-time or near real-time warehouse loading. Some of these tools and techniques are described below.
Solution 1a: "Near Real-time" ETL
The cheapest and easiest way to solve the real-time ETL problem is to not even attempt it in the first place. Not every problem actually requires, or can justify the costs of true real-time data warehousing. For these applications, simply increasing the frequency of the existing data load may be sufficient.
A data load that currently occurs weekly can perhaps be performed instead daily, or twice a day. A daily data load could be converted to an hourly data load. To get around the issue of system downtime, see Solution 1c below. This approach allows the warehouse users to access data that is more fresh than they are used to having, without having to make major modifications to existing load processes, data models, or reporting applications. While not real-time, near-real time may be a good inexpensive first step.
Solution 1b: Direct trickle feed
Assuming that an application requires a true-real time data warehouse, the simplest approach is to continuously feed the data warehouse with new data from the source system. This can be done by either directly inserting or updating data in the warehouse fact tables, or by inserting data into separate fact tables in a real-time partition (see Solution 2b).
How to actually transport the data between the operational systems and the data warehouse is beyond the scope of this article, but several approaches are worth mentioning. There are a number of new real-time data loading packages that are specifically designed for this challenge, including those from DataMirror and MetaMatrix.
EAI vendors such as Tibco provide solutions for real-time data transport. For systems based on the latest Java technologies, Java Messaging Service (JMS) can be used to transmit each new data element from the source system to a lightweight listener application that in turn inserts the new data into the warehouse tables. For data that is received over the Internet, the data can be transmitted in XML via HTTP using the SOAP standard, and then loaded into the warehouse.
Once the data is near the warehouse, simply inserting the new data in real-time is not particularly challenging. The problem with this approach, which will probably not be readily apparent during development and initial deployment, is that it does not scale well. The same logic as to why data warehouses exist in the first place applies-complex analytical queries do not mix well with continuous inserts and updates. Constantly updating the same tables that are being queried by a reporting or OLAP tool can cause the data warehouse's query performance to degrade.
Under moderate to heavy usage, either from concurrent warehouse user queries or from the incoming data stream, most relational database management systems will begin to temporarily block the incoming data transactions altogether, and the data will become stale. This may also cause the data loading application to fail altogether if the warehouse becomes unresponsive. Also as queries begin to slow and if the data becomes stale, the warehouse users may become frustrated and stop using the system altogether.
Two approaches to real-time data loading that help avert this scalability problem are described in the next section. Also the issue of real-time data warehouse scalability, and four additional approaches to building a scalable real-time warehouse system, are discussed in Section 4 of this paper.
Solution 1c: Trickle & Flip
The "Trickle & Flip" approach helps avert the scalability issues associated with querying tables that are being simultaneously updated. Instead of loading the data in real-time into the actual warehouse tables, the data is continuously fed into staging tables that are in the exact same format as the target tables. Depending on the data modeling approach being used (see section 2 below), the staging tables either contain a copy of just the data for the current day, or for smaller fact tables can contain a complete copy of all the historical data.
Then on a periodic basis the staging table is duplicated and the copy is swapped with the fact table, bring the data warehouse instantly up-to-date. If the "integrated real-time partition through views" approach is being used, this operation may simply consist of changing the view definition to include the updated table instead of the old table. Depending on the characteristics of how this swap is handled by the particular RDBMS, it might be advisable to temporally pause the OLAP server while this flip takes place so that no new queries are initiated while the swap occurs.
This approach can be used with cycle times ranging from hourly to every minute. Generally best performance is obtained with 5-10 minute cycles, but 1-2 minute cycles (or even faster) are also possible for smaller data sets or with sufficient database hardware. It is important to test this approach under full load before it is brought into production to find the cycle time that works best for the application.
Solution 1d: External Real-time Data Cache
All of the solutions discussed so far involve the data warehouse's underlying database taking on a lot of additional load to deal with the incoming real-time data, and making it available to warehouse users. The best option in many cases is to store the real-time data in an external real-time data cache (RTDC) outside of the traditional data warehouse, completely avoiding any potential performance problems and leaving the existing warehouse largely as-is.
The RTDC can simply be another dedicated database server (or a separate instance of a large database system) dedicated to loading, storing, and processing the real-time data. Applications that either deal with large volumes of real-time data (hundreds or thousands of changes per second), or those that require extremely fast query performance, might benefit from using an in-memory database (IMDB) for the real-time data cache. Such IMDBs are provided by companies such as Angara, Cacheflow, Kx, TimesTen, and InfoCruiser.
Regardless of the database that is used to hold the RTDC, its function remains the same. All the real-time data is loaded into the cache as it arrives from the source system. Depending on the approach taken and the analytical tools being used, either all queries that involve the real-time data are directed to the RTDC, or the real-time data required to answer any particular query is seamlessly imaged to the regular data warehouse on a temporary basis to process the query. These two options are described in detail in Solutions 4c and 4d below.
Using an RTDC, there's no risk of introducing scalability or performance problems on the existing data warehouse, which is particularly important when adding real-time data to an existing production warehouse. Further, queries that access the real-time data will be extremely fast, as they execute in their own environment separate from the existing warehouse.
This is important as users who need up-to-the-second data typically don't want to wait too long for their queries to return. Also by using just-in-time data merging from the RTDC into the warehouse, or reverse just-in-time merging from the warehouse into the RTDC (described in Solutions 4d and 4e), queries can access both real-time and historical data seamlessly.
The downside of using a RTDC solution, with or without just-in-time data merging, is that it involves an additional database that needs to be installed and maintained. Also there is additional work required to configure the applications that need to access the real-time data so that they point to the RTDC. The upside of the RTDC is increased performance, access to up-to-the-second data, and no scalability or performance risk on the existing warehouse. Also the cost of an RTDC solution is typically low compared to the cost to add sufficient hardware and memory to the existing database server to overcome the scalability and performance issues associated with the trickle feed approaches.
Challenge #2: Modeling Real-time Fact Tables
The introduction of real-time data into an existing data warehouse, or the modeling of real-time data for a new data warehouse brings up some interesting data modeling issues. For instance, a warehouse that has all of its data aggregated at various levels based on a time dimension needs to consider the possibility that the aggregated information may be out of synch with the real-time data. Also some metrics such as month-to-date and week-to-date may behave strangely with a partial day of data that continuously changes. The main issue regarding modeling however revolves around where the real-time data is stored, and how best to link it into the rest of the data model.
Solution 2a: Modeling as Usual with Direct Fact Table Feed
When using the Direct Trickle Feed or Trickle & Flip approaches to real-time ETL discussed above, and when the real-time data is stored along with the historical data in the same fact tables, no special data modeling approaches are required. From the query tool's perspective, there is nothing different about a real-time data warehouse modeled in this manner than from a non-real-time warehouse.
The main thing to consider when using this approach is caching. Many query, reporting, and OLAP tools will cache reports and result sets, and assume that these caches need to be refreshed only upon the nightly or weekly warehouse load. With a real-time data feed, this type of caching needs to be either disabled, or set to the same cycle as the table flip when using the Trickle & Flip approach. Since most query tools do not have a good mechanism for coordinating cache expiration with frequent external events, disabling caching for the reports that run on real-time data is usually the best approach. In the future it is likely the query tools will become more real-time aware, and understand that some tables are frequently changing and vary their caching approaches accordingly, but for now these settings need to be set carefully and by hand.
Solution 2b: Separate Real-time Partition
One approach to modeling real-time data is to store the real-time data in separate warehouse fact tables. Depending on the type of fact table, many query tools that support table partitioning will be smart enough to automatically retrieve the real-time data from the real-time tables when required. For tables where this will not work, alternate facts and attributes can be set up to point to the real-time data tables, and the query tool can be set up to drill across from reports containing the historical data to real-time data templates.
From the query-tool configuration and administration perspective, this data modeling approach is the most complex to engineer. This approach requires either the query tool or the end user to understand where the various types of data are located and how to access them. The success of this approach depends significantly on how well the query tool insulates the end user from the extra complexities required to access real-time information.
This data modeling approach is covered in detail by Ralph Kimball in his February 2002 "Real-time Partitions" article in Intelligent Enterprise (http://www.intelligententerprise.com/020201).
Solution 2c: Integrated Real-time through Views
Another real-time data modeling approach is to store the real-time data in different tables from historical data, but in the same table structure. Then by using database views, the historical and real-time data tables are combined together so that they look like one logical table from the query tool's perspective. This helps alleviate many of the problems associated with the separate partition approach, as the query tool or end users do not need to join two tables.
This approach is similar to the direct fact table feed, except the feed is into smaller tables that can be more easily modified or replaced when necessary by the load process. Also these tables will generally be small enough to sit in the database's memory cache, to alleviate some of the query contention issues involved with performing OLAP queries on changing data. The caching concerns discussed in Solution 2a still apply, and care needs to be taken to ensure that the query tool doesn't return old cache results to users who are requesting real-time data.
Solution 2d: Modeling with an External Real-time Data Cache
When using an external real-time data cache, no special data modeling is required in the data warehouse. The external data cache database is generally modeled identically to the data warehouse, but typically contains only the tables that are real-time.
If the external data cache is accessed separately from the data warehouse (using a separate OLAP project, for example), some additional tables may be required in the cache, such as lookup tables. But external data caching is most useful when the data is seamlessly integrated with historical data for query and analysis purposes.
The advantage of this approach from a data modeling perspective is similar to using a direct fact table feed or performing integrated real-time through views (discussed in Solutions 2a and 2c). This approach has the additional advantage of eliminating performance problems associated with the other approaches to integrating real-time data into a data warehouse. These approaches are discussed in more detail in Solutions 4c, 4d, and 4e.
Challenge #3: OLAP Queries vs. Changing Data
OLAP and Query tools were designed to operate on top of unchanging, static historical data. Since they assume that the underlying data is not changing, they don't take any precautions to ensure that the results they produce are not negatively influenced by data changes concurrent to query execution. In some cases, this can lead to inconsistent and confusing query results.
Relational OLAP tools are particularly sensitive to this problem because they perform all but the simplest data analysis operations by issuing multi-pass SQL. A multi-pass SQL statement is made up of many smaller SQL statements that sequentially operate on a set of temporary tables. For example, the simple report below shows sales for a retailer at the category level along with a percent-to-total calculation:
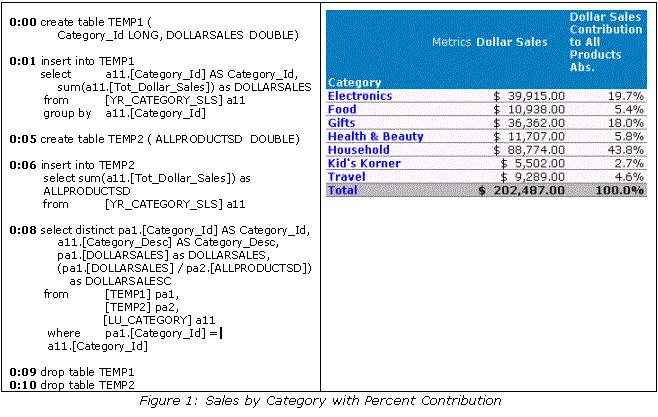
While this report is simple, the SQL that is used to generate it by a leading OLAP tool is surprisingly complex. Note that two temporary tables are created, loaded with intermediate results, then a final pass is run, and the two temp tables are then dropped. The first temporary table is loaded with the totals for sales at the category level. The second temp table holds only one row, the total sales for all categories. The final SELECT statement then joins the two temporary tables together with the fact table to generate the final result set.
This works fine when the data is static, but what if the underlying data changes while the first temp table is being created? Most database systems will return the data that was current at the point that the query started to run. Notice the times in bold before each statement. The INSERT statement into TEMP1 ran for four seconds, and the query to load data into TEMP2 started at second 6. This means that TEMP1 will contain data current as of 0:01, but TEMP2 will contain data current as of 0:06. If a few large sales were registered during those 5 seconds, they will be included in the total dollar amount contained in TEMP2, but won't be represented in the category-level data that is in TEMP1. When the data is brought together in the final SELECT statement, the total in TEMP2 will be larger than the sum of the categories in TEMP1. This will cause the resulting report to show an incorrect total, and the total percentage number will be less than 100%! Also, in this example, the result that is displayed, besides being internally inconsistent, is already 10 seconds old.
This example actually represents the best case for most real-world relational OLAP systems. Many users experience query response times that run from tens of seconds to multiple hours. For a well-tuned application, acceptable response times typically run from 15 seconds to 2-5 minutes. Also typical OLAP queries can contain many pages of SQL code. While our example contained only 6 passes of SQL, it is not uncommon for reports to consist of 10-50 passes.
This presents two problems. The first problem is that the results of a query that takes even one minute are arguably not exactly real-time anymore. While this data latency may be acceptable to a retail division manager, it might not be ok for an application that is looking for atmospheric trends that indicate the presence of a tornado, or for an application detecting real-time credit card or telecommunications fraud.
The second problem is that given the multiple passes of SQL required to perform almost any relational OLAP reporting or analytical operation, any real-time warehouse is likely to suffer from the result set internal inconsistency issue discussed above. There's nothing like the numbers not adding up properly to make a user skeptical of a report. For more complex product affinity or trend detection analytics, the results may be so confusing as to be completely useless.
The next three solution sections discuss ways to alleviate this problem while still retaining real-time or near-real-time reporting and analytics.
Solution 3a: Use a Near Real-time Approach
As in the first challenge, an easy way around this challenge is to avoid the whole issue in the first place. This report consistency issue is only a problem when the data is changing quickly enough so that the data will be different at the end of a multi-pass query execution cycle than it was at the beginning. Using either the Near-real-time ETL approach (Solution 1a) or the Trickle & Flip approach with a relatively long cycle time (Solution 1c) will alleviate this problem if the OLAP server is instructed not to send new jobs to the data warehouse during the load or flip.
The downside is that the data is not really real-time, but is "delayed" like some free stock market sites on the Internet. Also if the ETL or flipping process takes too long, it is possible that users will become frustrated by delayed or timed-out queries. Care must be taken to ensure that the OLAP server can be properly paused during the load or flip.
Solution 3b: Risk Mitigation for True Real-time
Assuming a near-real-time approach is not sufficient for an application, there are some ways to mitigate the affects of report data inconsistency. The simplest is to not allow users to perform the most complex queries on the real-time data. An alternative is to have a less-frequently updated snapshot of the real-time data in a separate partition that can be used for complex analytical queries. This however adds a lot of setup, maintenance, and user education complexity.
If an application is going to need to live with some internal report inconsistency, it is important to educate the users of the real-time information that this is a possibility. Uneducated users who view data that doesn't properly add up are likely to assume that the system is malfunctioning and can't be trusted.
Solution 3c: Use an External Real-time Data Cache
The only way to completely solve this problem without compromising report internal consistency, data latency, or the user experience is to use an external real-time data cache. By keeping the real-time data separate from the historical data, the reports will never be internally inconsistent. It is still possible though to do seamless reporting on historical and real-time data using a just-in-time data merge process, which is described in Solution 4d below. Also the issue of reporting latency can be addressed using a reverse just-in-time data merge into a memory-based real time data cache. This approach is discussed in Solution 4e.
Challenge #4: Scalability & Query Contention
The issue of query contention and scalability is the most difficult issue facing organizations deploying real-time data warehouse solutions. Data warehouses were separated from transactional systems in the first place because the type of complex analytical queries run against warehouses don't "play well" with lots of simultaneous inserts, updates, or deletes.
Usually the scalability of data warehouse and OLAP solutions is a direct function of the amount of data being queried and the number of users simultaneously running queries. Given a fixed amount of data, the number of users on the system is proportional to query response time. Lots of concurrent usages causes reports to take longer to execute.
While this is still true in a real-time system, the additional burden of continuously loading and updating data further strains system resources. Unfortunately the additional burden of a continuous data load is not just equivalent to one or two additional simultaneously querying users due to the contention between data inserts and typical OLAP select statements. While it depends on the database, the contention between complex selects and continuous inserts tends to severely limit scalability. Surprisingly quickly the continuous data loading process may become blocked, or what used to be fast queries may begin to take intolerably long to return.
There are ways to get around this problem, including the near-real-time approaches described in previous sections, but where true real-time is a hard and fast requirement, the approaches described below help to address this problem in various ways.
Solution 4a: Simplify and Limit Real-time Reporting
Many real-time warehousing applications are relatively simple. Users that want to see up-to-the-second data may have relatively simple reporting requirements. If reports based on real-time data can be limited to simple and quick single-pass queries, many relational database systems will be able to handle the contention that is introduced. Frequently the most complex queries in a data warehouse will be accessing data across a large amount of time. If these queries can be based only on the non-changing historical data, contention with the real-time load is eliminated.
Another important consideration is to examine who really needs to be able to access the real-time information. While real-time data may be interesting to a large group of users within an organization, the needs of many users may be adequately met with non-real-time data, or with near-real-time solutions.
Also many users who may be interested in real-time data may be better served by an alert notification application that sends them an email or wireless message alerting them to real-time data conditions that meet their pre-defined thresholds. Designed properly, these types of systems can be scaled to 100 or 1000 times more users than could possibly run their own concurrent real-time warehouse queries (see Section 5 for more details).
Solution 4b: Apply More Database Horsepower
There is always the option of adding more hardware to deal with scalability problems. More nodes can be added to a high-end SMP database system, or a stand-alone warehouse box can be upgraded with faster processors and more memory. While this approach may overcome short-term scalability problems, it is likely to only represent a band-aid approach. Real-time query contention often has more to do with the fundamental design of a RDBMS than with the system resources available.
Solution 4c: Separate & Isolate in a Real-time Data Cache
Using an external real-time data cache (described above in Solution 1d) solves the scalability and query contention problem by routing all real-time data loading and query activity to an independent database that can be tuned for real-time access. With all the real-time activity on the separate cache database, the data warehouse does not bear any additional load.
However this approach, on its own, is not an entirely satisfactory solution. With the real-time data external to the warehouse, it is not possible for a single report or analysis to join or co-display real-time and historical information. Further, if complex analytical reports are run on the real-time cache, it is possible for the cache to begin to exhibit the same internal report inconsistency, database contention, and scalability problems that a warehouse would exhibit.
This approach on its own, without the additional functionality described in the next two Solutions, does work well for some stand-alone real-time reporting, analysis, and alerting applications, particularly those with few concurrent users and those with limited or no need for historical data.
Solution 4d: Just-in-time Information Merge from External Data Cache
There is a class of applications whose needs are not met by the approaches described so far in this paper. They tend to share two or more of the following characteristics:
- Require true real-time data (not near-real-time)
- Involve rapidly-changing data (10-1000 transactions per second)
- Need to be accessed by 10s, 100s, or 1000s of concurrent users
- Analyze real-time data in conjunction with historical information
- Involve complex, multi-pass, analytical OLAP queries
These applications require the best aspects of a traditional data warehouse such as access to large amounts of data, analytical depth, and massive scalability. They also require the access to real-time data and processing speed provided by a real-time data cache. For these applications it is necessary to use a hybrid approach. The real-time information sits in an external data cache, and the historical information sits in a warehouse, and the two are efficiently linked together as needed. This can be accomplished by an approach known as just-in-time information merging (JIM).
In a JIM system, queries that require real-time data are pre-processed by the a component known as the JIM Request Analyzer (JIM-RA). The JIM-RA analyzes the query to determine exactly what real-time data components are required. Then the JIM Data Imager (JIM-DI) component takes a snapshot image of the required parts of the real-time data cache. The real-time data from the snapshot is then loaded into temporary tables in the data warehouse by the JIM-DI component. Once the real-time data is present, the JIM-RA modifies the original query to include the temporary tables containing the snapshot data.
This approach allows existing BI and OLAP tools to seamlessly access real-time information within the framework of existing data warehouse applications. There is no possibility of introducing scalability problems, as the required real-time data is only brought into the warehouse when needed, and on a temporary independent one-off basis for each query. Data modeling is relatively simple, and can be approached as described above in Solutions 2a and 2b. Query contention is not a problem as the data does not change while it is being queried. Also there is no risk of report inconsistency, as the real-time information is held constant in the snapshot between the multiple passes of SQL.
lution 4e: Reverse Just-in-time Data Merge
A variant of JIM is Reverse Just-in-time Data Merging (RJIM). Reverse JIM is useful for queries that are mainly based on real-time data, but that contain limited historical information as well. In Reverse JIM a similar process takes place, except the needed historical information is loaded from the data warehouse into the external data cache on a temporary basis, and then the query is run in the data cache. This only works when the data cache is located in a RDBMS system with full SQL support, and will not work with some IMDB systems that do not support many SQL functions.
An intelligent RJIM system needs to process as much of the query as possible on the warehouse before transferring only the data required at the highest level of summarization required for each query. Otherwise an RJIM system could easily overflow an external data cache with large amounts of historical information. The best systems are able to use both JIM and RJIM, and decide which process to use for each query based on the amount of data that is likely to go in either direction, and choose the path of least resistance and likely best performance.
While this article has given an overview of JIM and RJIM approaches, the details regarding how to implement such systems are beyond its scope, and the technologies and tools required are quickly developing.
Challenge #5: Real-time Alerting
Most alerting applications associated with data warehouses to date have been mainly used to distribute email versions of reports after the nightly data warehouse load. The availability of real-time data in a data warehouse makes alerting applications much more appealing, as users can be alerted to real-time conditions as they occur in the warehouse, not just on a nightly basis.
The availability of real-time data makes products such as MicroStrategy's NarrowCaster and similar products from Cognos and Business Objects very valuable. But real-time alerting using these products brings its own set of challenges, as surprisingly these products, like many query tools from the same vendors, were not designed to operate on or tested against real-time data feeds.
These products operate on a schedule or event basis, so they can either trigger an alert every few minutes or hours, or need to be triggered by an external system. These challenges will be addressed in Solutions 5a and 5b below. There is also the issue of threshold management. When alerts are triggered frequently (as opposed to once a night upon warehouse load), there needs to be a mechanism in place to make sure that once an alert is sent due to a condition in the warehouse that the alert is not continuously sent over and over again during each alerting cycle. A way to solve this problem is presented in Solution 5c below.
Solution 5a: n-Minute Cycle Schedule
Currently all data warehouse alerting technology works on a schedule basis or on an event basis. This means to perform true real-time alerting, a process needs to continuously monitor the incoming data and trigger the events when appropriate. This approach is discussed in Solution 5b below.
One way to approximate real-time alerting, without the added complexity of a real-time data stream monitoring solution, is to utilize a data warehouse alerting package on a scheduled basis, with the schedule typically set to every 1, 5, 15, or 30 minutes. This approach works reasonably well and provides near-real-time alerting. For a warehouse that is loaded on a near-real-time basis, all that needs to be done is to set the alerting schedule to trigger right after the data is refreshed.
For a warehouse that is being updated on a truly real-time basis, then using a n-minute cycle schedule will introduce a certain amount of latency, as an alert can't be triggered until the next cycle window comes around after the threshold condition is met. If the cycle time is low enough, and the alert is to be sent via email anyway, a 1 or 5 minute latency may be acceptable for many applications.
It is appealing to set the cycle threshold as low as possible, but this can introduce certain complications. Frequent alert cycles will introduce more load on the data warehouse, which can impact performance for other users. Also, if a cycle begins before the previous cycle has completed, it is possible for users to receive duplicate alerts (see Solution 5c below). Some tools will overwrite temporary work tables if another batch is triggered before the previous one completes, which can cause system errors or missing alerts.
Until more sophisticated alert cycle pipelining technology is added to current alerting tools, it is important to choose a cycle window that will provide enough time for the previous batch of alerts to be completed before the next begins.
Solution 5b: True real-time data monitoring & triggering
For true real-time data alerting, a triggering system needs to be in place, as existing data warehouse alerting systems are not capable of monitoring real-time data streams looking for exception conditions. General-purpose versions of such technologies are currently under development by companies such as Apama, but in the short-term custom solutions optimized for the task and data stream at hand are the best solutions.
These systems are fairly complex, and depending on the number of users and alert conditions, and on the amount of incoming data, can require large amounts of hardware and particularly memory. Imagine a system providing real-time stock market alerts for 100,000 users. 100k portfolios and alert thresholds need to be stored in memory and compared against every incoming tick from the various stock markets, which can be hundreds or thousands per second during market hours. This is a very difficult task, and currently there are no general-purpose technologies that can meet these needs.
Solution 5c: Real-time Alert Threshold Management
Regardless of whether alerts are generated using near-real-time batch cycles or by a real-time triggering system, it is critically important that the users' alert thresholds are properly managed. Imagine a user who asks to be alerted by email when the inventory level of any item in his store drops to 5% of the normal level during the course of a day. The user assumes that he or she will be alerted once when the level drops to 5%, but with a system running on a 5 minute cycle, a new alert will be send every 5 minutes!
The problem occurs when static threshold definitions, which are fine for systems that load on a nightly or weekly basis, are applied to systems that update more frequently. It is unlikely that the user desires to be reminded every 5 minutes. It might be better to alert the user once levels reach 5%, and then maybe again at 2%, and then one final time when stock runs out completely. Or a brokerage customer may want to know when a certain stock exceeds $20, and then be alerted again every increment of $2 it goes higher.
This type of threshold management is necessary for real-time alert systems to be accepted by users. Unfortunately it is not natively supported by current warehouse alerting tools. Until this support is added, the best approach is to use the tools' post-service plug-in abilities to run custom SQL or procedures to directly update the user's thresholds based on the current data conditions. It is this post-execution job that make it critical that cycles don't overlap, as if the next batch begins before the thresholds are updated, it is likely that duplicate alerts will be sent.
Summary: Real-time with Today's Technology
As we have seen in this article, real-time data warehousing and OLAP are possible using today's technology, but challenges lurk seemingly every step of the way. For the determined team armed with the right knowledge and experience, it is possible to make real-time reporting, analysis, and alerting systems work. The challenge is to make the right tradeoffs along the way, to make sure the systems meet the needs of the user base while ensuring that they don't collapse under their own weight, or cause existing production warehouses to malfunction
It is likely that a lot of the challenges discussed in this paper will become less challenging over time, as database, ETL, OLAP, reporting, and alerting tool vendors begin to add features to their systems to make them work better with real-time data streams. In the meantime, it is important to make sure real-time warehousing systems are well planned and designed, and thoroughly tested under realistic data and user load conditions before they are deployed.
The benefits of data warehousing in real-time are becoming clearer every day. With the right tools, designs, advice, approaches, and in some cases tricks, real-time data warehousing is possible using today's technologies, and will only become easier in the future. In any case, the time to begin planning and prototyping is now.
About the Author
Justin Langseth is a founder and CTO of Claraview LLC. Prior to founding Claraview, Mr. Langseth was founder and CTO of Strategy.com, a real-time data analysis and alerting subsidiary of MicroStrategy. At Strategy.com, he designed and implemented systems that provided near real-time and real-time reports and alerts to over 350,000 users, via web, email, wireless, and voice technologies.
About Claraview
Claraview delivers business intelligence and data mining solutions for commercial enterprises and government agencies. The company’s team of business intelligence experts attacks the most pressing data challenges with passion, delivering a full-range of services including needs assessments, architecture design, project management, and application development. Our approach calls for intimate involvement by Claraview senior management on every engagement. This model has delivered scalable business intelligence systems on time and on budget to many well-known organizations including Lowe’s Companies, Inc., KeySpan Energy, the Public Company Accounting Oversight Board, Office Depot, Vivendi, The U.S. Department of Education, and the Federal Election Commission. Challenge us to make business intelligence work. For more information visit www.claraview.com or call 571-226-0020.
Citation
Langseth, J., "Real-Time Data Warehousing: Challenges and Solutions", DSSResources.COM, 02/08/2004.
Jeffery Erber, Director of Marketing, Claraview, LLC , provided permission to feature this article and archive it at DSSResources.COM on Monday, December 1, 2003. The article is copyright © 2002 Claraview LLC. All Rights Reserved. The article is used by permission. You can contact Jeff Erber at 571-226-0020 and email: jeff.erber@claraview.com. This article was posted at DSSResources.COM on February 8, 2004.